
Introduction
One of the pivotal moments in deep learning history was the development of LeNet-5 in 1998. Research into neural networks had begun decades prior but had reached a lull. LeNet-5 ended that lull by showing that neural networks were capable of achieving state-of-the-art results in tasks that were notoriously difficult at the time, such as optical character recognition. This model, created by Yann LeCun, was part of the first deep learning image recognition models using convolutional neural nets. It was trained to identify the handwritten digits below, familiar to everyone who studies machine learning as the MNIST dataset. Nowadays, neural networks achieve state-of-the-art results in many of the domains they are applied to.

When I was taught machine learning at university, I was thrown straight into deep learning with neural networks. In fact, the introductory course offered was aptly called “Deep Learning with Artificial Neural Networks.” This was rightly done since after all neural networks dominate the field. However, it’s a fun exercise to take a step back and see what I wasn’t taught, to see exactly why I was instructed to go straight into neural nets and not bother with other elementary approaches.
Machine learning without neural networks can, of course, be done. Reinforcement learning is a large area of research under the ML umbrella that doesn’t necessarily rely on deep learning. Still the prominence of deep learning with neural nets is huge. In this post, I am trying to take a task commonly solved by DL approaches, the MNIST classification task, and see if we can train a model without using neural nets, backpropagation, or any of the now ubiquitous techniques.
Classification via Pixel Similarity
I was reading the practical deep learning textbook where the authors introduced how one could perform image recognition by creating the ‘mean’ of each digit, a single image representing what an ideal form of each number should look like. I’ve put some examples below. Then, you can classify unseen numbers by comparing a sample to each of these ideal forms. You can calculate how ‘different’ the sample is from each ideal digit using a variety of loss functions— I chose to go with mean absolute error. The ideal form with the smallest loss from the sample would categorize your number. This is a classic approach to digit classification with decent results.

The authors went on to suggest that improving upon these results requires turning to deep learning: “Our pixel similarity approach does not… have any kind of weight assignment, or any way of improving based on testing the effectiveness of a weight assignment. In other words, we can’t really improve our pixel similarity approach by modifying a set of parameters.” At this point, the authors introduce deep learning—learning with neural networks and stochastic gradient descent—as the clear way to improve model performance. However, I had another idea.
Improvement without Backpropagation
The authors overlooked that we do actually have some hidden parameters here! Our model is essentially trained on the images used to build the ‘ideal’ version of each digit. To improve its performance, we can look at digit samples the model fails to identify and adjust our ‘ideal’ numbers to better encompass these misfits by giving them more weight when building the optimal version of the corresponding digit.
The book only demonstrates identifying 3s vs. 7s, which is fair since their purpose is to move on quickly to the SGD approach. However, since we aim to modify their pixel-similarity approach to achieve actual learning, I expanded their code to work with all digits, which was easy enough. The resulting average accuracy across all digits in the validation set is 64%. While far from production-quality, it’s significantly better than a random guess accuracy of 10%. Let’s see how much better we can do by introducing some machine learning—but not deep learning.
My idea was that after performing one step, we could examine which samples the pixel-distance model fails to classify correctly, then weigh those misfits more heavily while recalculating the ‘ideal digit’ forms. We can repeat this process until performance plateaus or decreases. In this way, we update the model to better fit each digit without using neural networks or gradient descent.
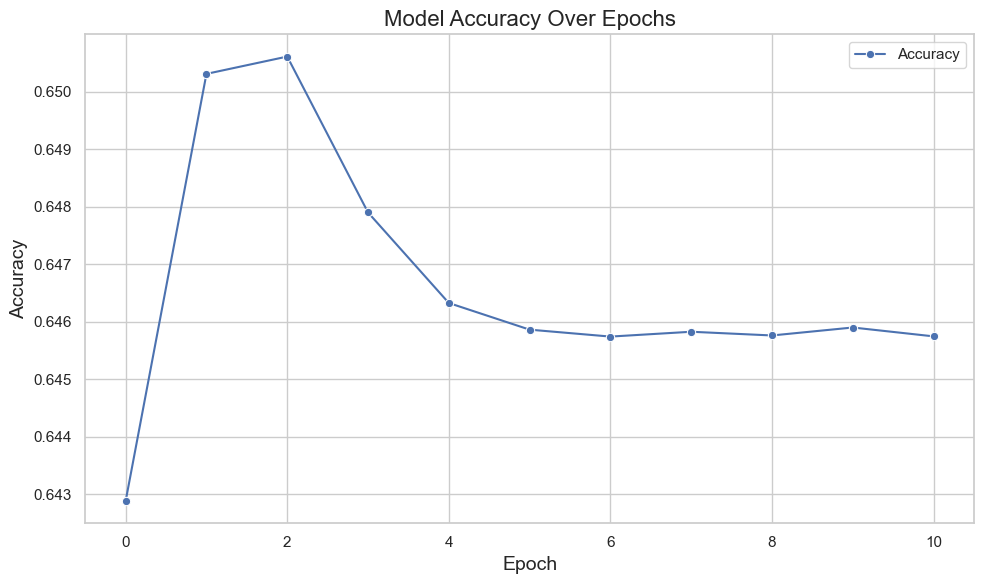
The plot above shows the accuracy of the model each time we repeat the described process. You can see an improvement in performance—the model learned! Using this simple technique, we improved the performance of this pixel-distance classification model. However, there is a notable drop-off after the second step. While still better than the baseline, the performance isn’t strictly improving as we’d hope. This drop-off likely happens because the model starts to overvalue the misfits. Since it is trained and validated on different datasets, the model learns specific misfits from the training set, not present in the validation set. Our non-deep-learning machine learning model is overfitting!
An easy fix is to value the learned knowledge a tad less in each step, similar to setting a learning rate in gradient descent, where we take progressively smaller steps toward the local minimum. Instead, we’re just weighting each round of training slightly less, preventing unique outliers from overly influencing the results.
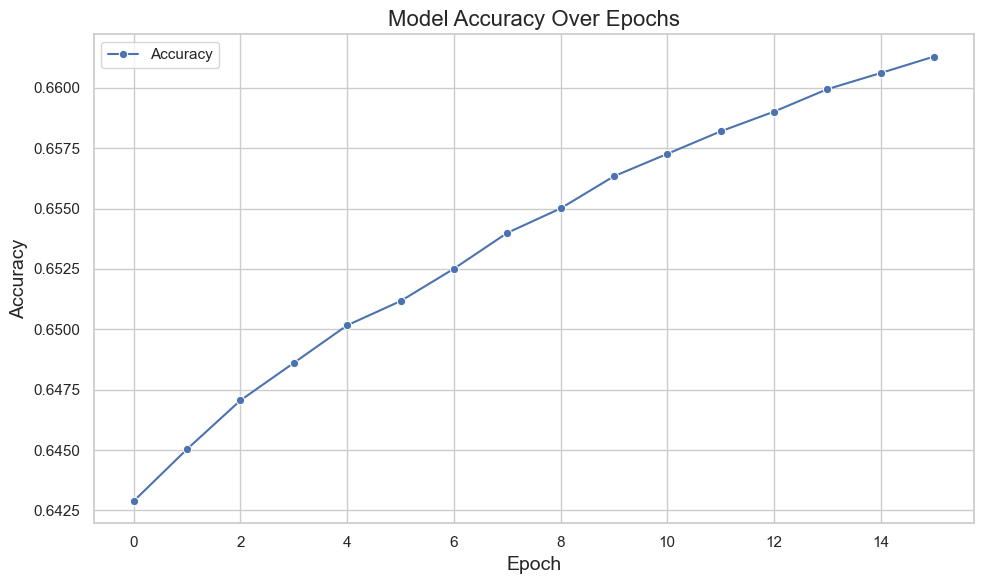
Perfect! Now our learning curve actually converges toward some improved performance, clearly an improvement. It’s interesting to observe that problems like overfitting and solutions like learning rates still arise in machine learning outside deep learning. It’s unsurprising, but since we usually jump straight into deep learning, seeing these concepts appear elsewhere is fascinating. But it makes me wonder what other common deep learning optimizations like momentum, regularization, or cross-validation could be brought over to improve performance further.
Conclusion
LeNet-5, the deep learning model I mentioned at the beginning of this blog post, achieved 98.4% classification accuracy on the MNIST dataset. Modern DL architectures get greater than 99% validation accuracy. Compared to these, the baseline and trained mean-pixel-distance models perform abysmally.
Our model’s final performance remains modest, and the gain in accuracy from training is minimal, but that’s not the point. What’s interesting is that we built a learning model devoid of neural networks. The authors overlooked an opportunity for learning without deep learning. Clearly, this classical approach wasn’t going to achieve state-of-the-art optical character recognition results, reinforcing that deep learning is king. Still, experimenting with non-neural network machine learning is enjoyable and underscores the importance of deep learning. I no longer merely take professors at their word—I’ve confirmed for myself that deep learning deserves its reverence.
If you would like to see the code I wrote for this post, it is available here.